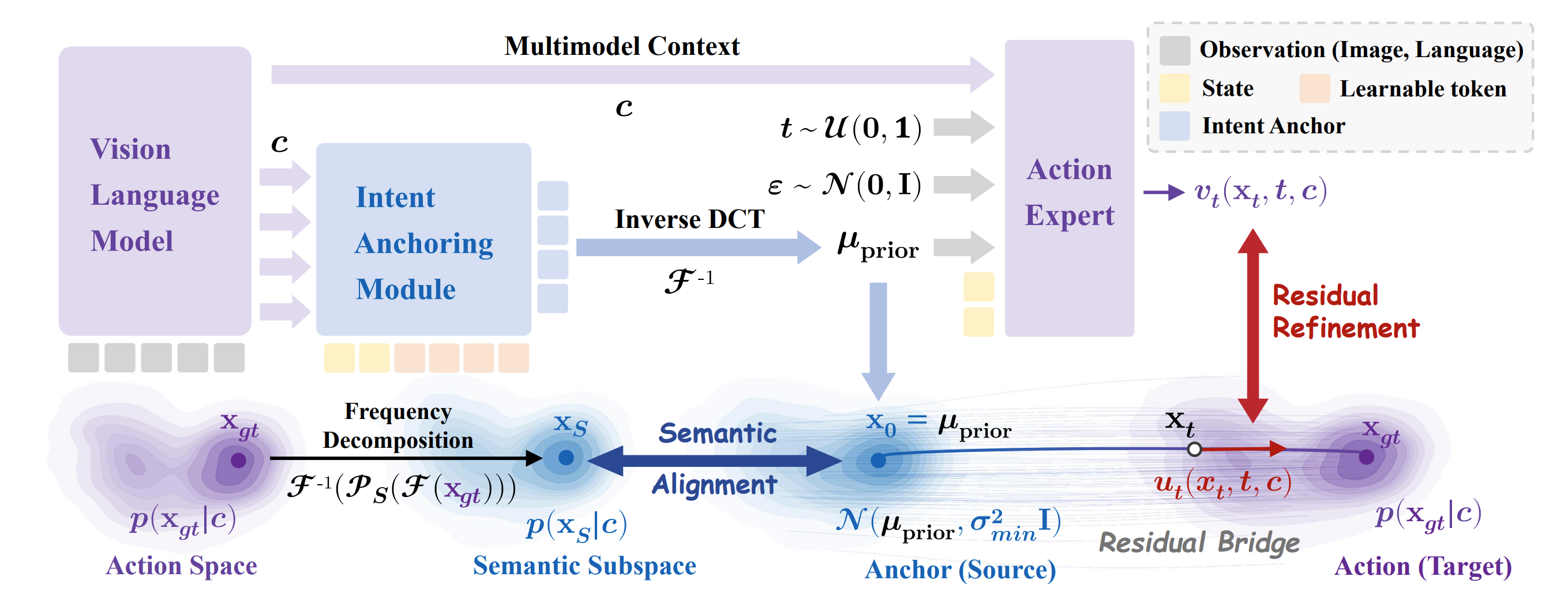
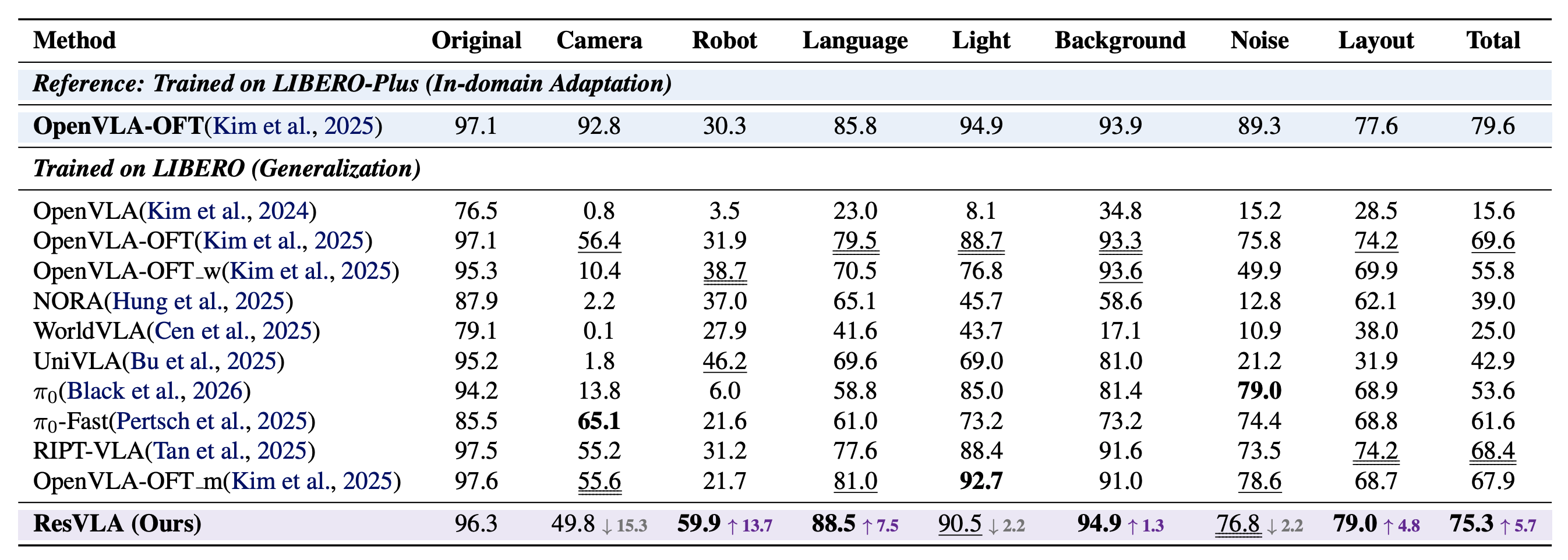
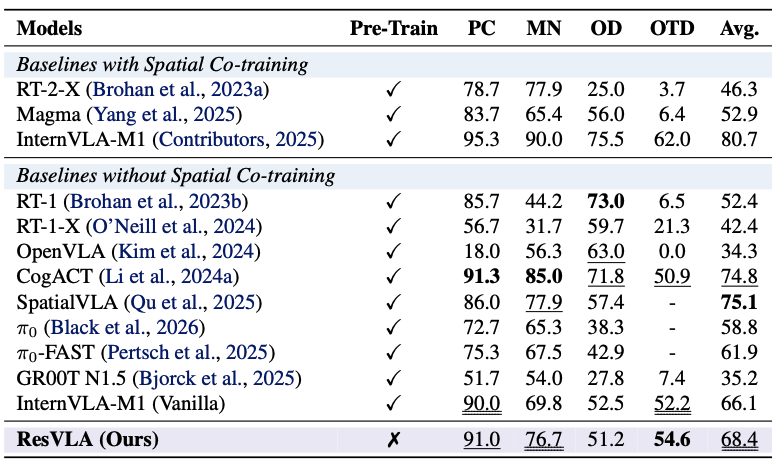
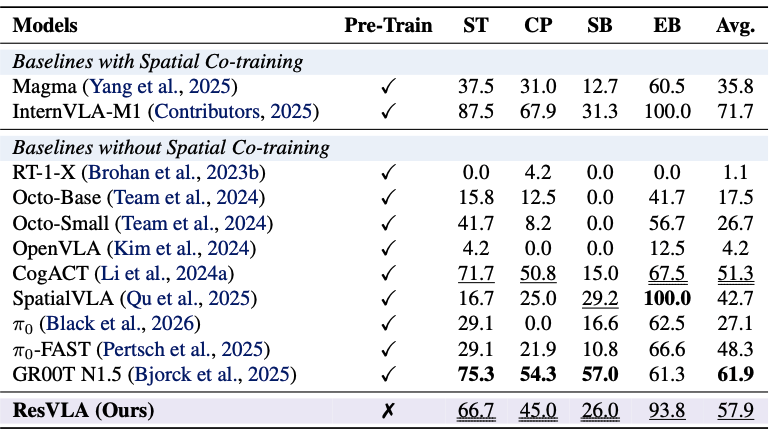
From Noise to Intent: A Paradigm Shift
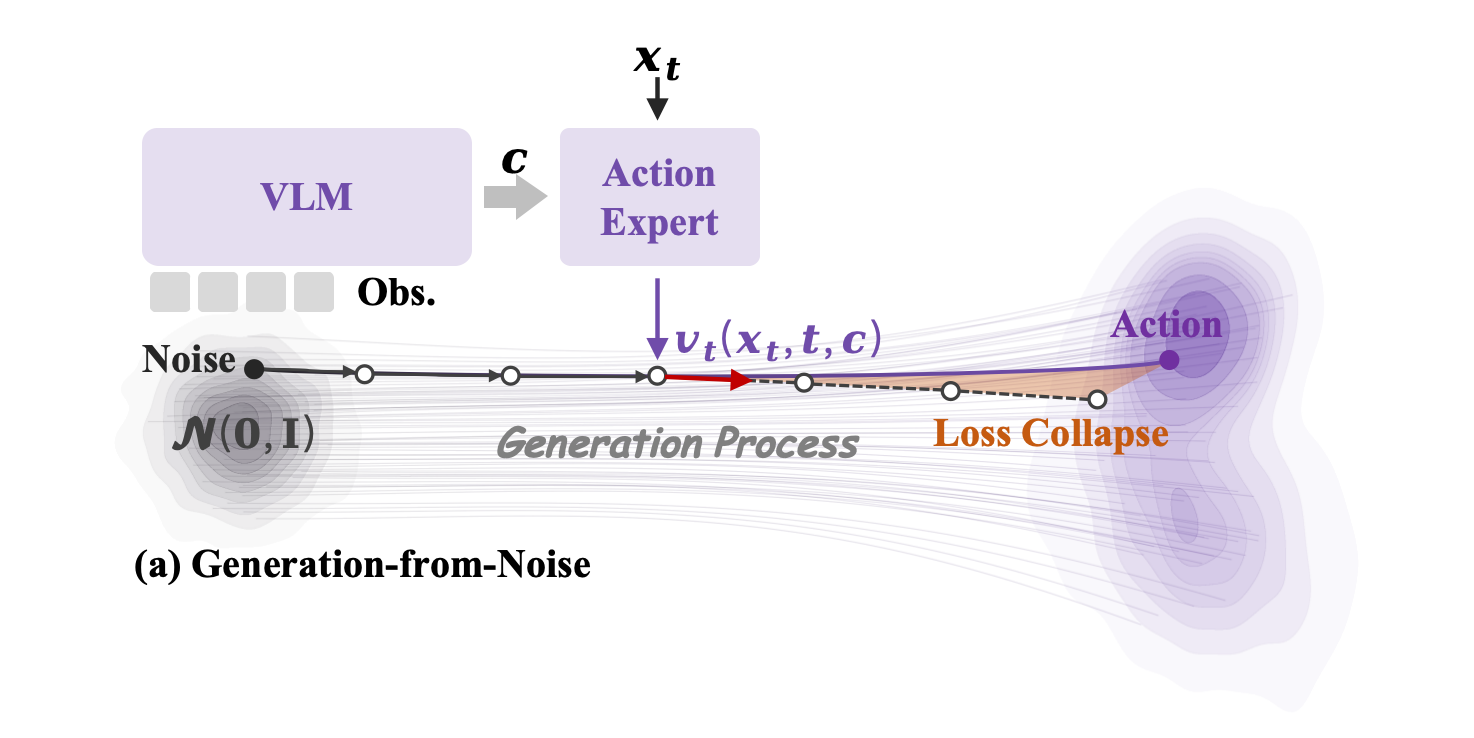
(a) As illustrated on the left, existing continuous generative policies typically adopt a "Generation-from-Noise" approach. The generation process starts from pure noise with no semantic prior (an uninformative, isotropic Gaussian distribution). Because the initial state is entirely independent of the task instructions, the model is forced to reconstruct the explicit global intent from scratch, resulting in a significantly long transport path. This blind exploration is not only computationally inefficient but also makes the optimization highly prone to "semantic drift" (a phenomenon known as "Loss Collapse"), where the model fails to align with fine-grained language instructions and generates trajectories that completely miss the target action manifold.
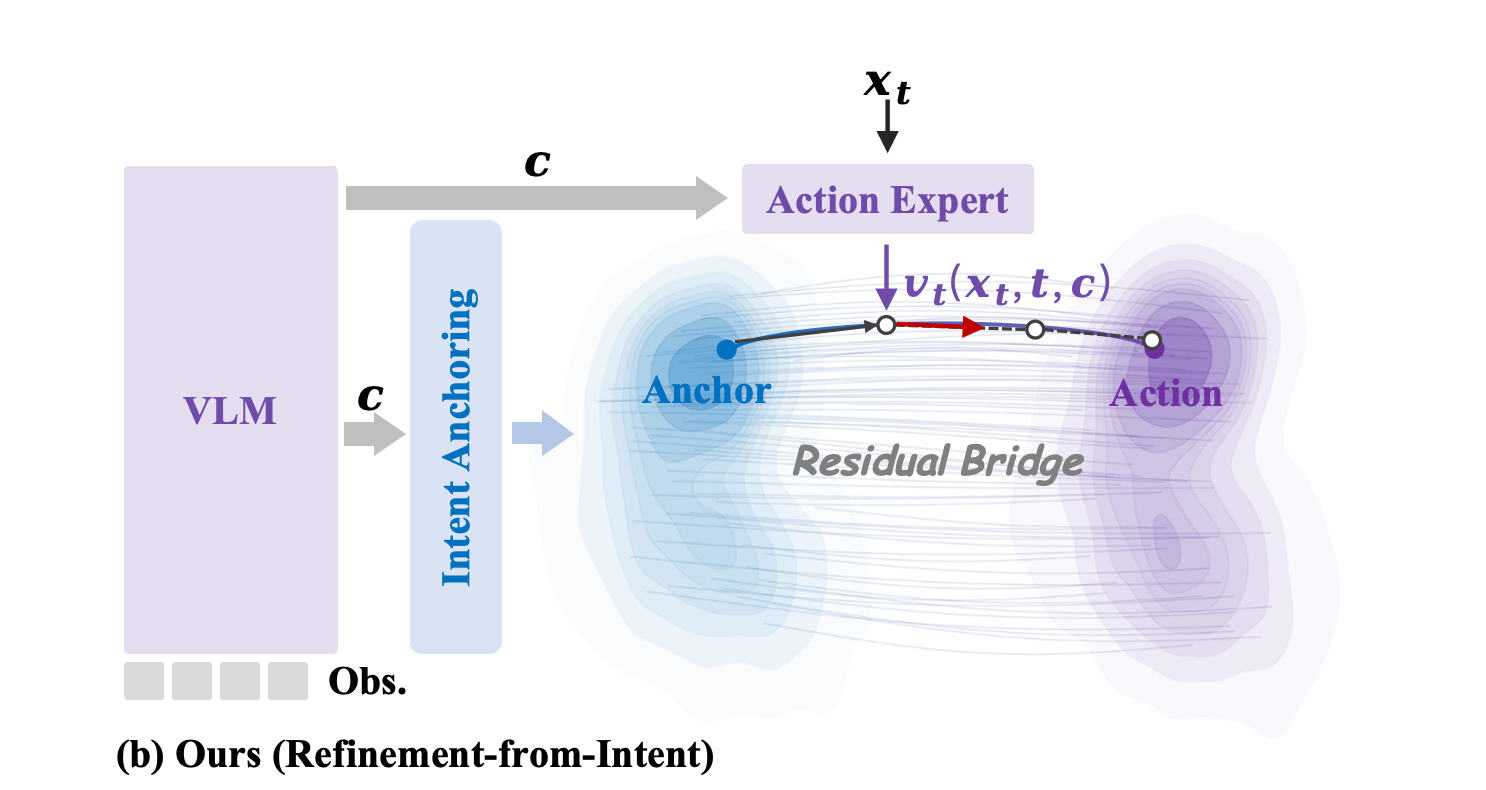
(b) To overcome these limitations, we propose a novel "Refinement-from-Intent" paradigm, shown on the right. Instead of generating actions ex nihilo, ResVLA starts from a condition-dependent intent anchor—a deterministic, low-frequency global trajectory structure directly predicted by the VLM. This mechanism provides a strong semantic prior before generation, effectively locking in the global spatial and semantic constraints. Consequently, a "Residual Diffusion Bridge" is established, allowing the generative model to refine residual dynamics only (i.e., the high-frequency execution details like contact adjustments). By transforming generation into a short-path refinement process, ResVLA dramatically improves inference efficiency, accelerates training convergence, and inherently prevents semantic drift.